
검색엔진
검색엔진을 이용하다보면, 검색어를 타이핑 하는 순간 연관된 추천 검색어들이 나오는 것을 알 수 있습니다. 어떻게 사용자가 타이핑을 하는 그 '찰나'에 추천 검색어를 찾아 낼 수 있었을까요? 그리고 많은 인터넷 문서들 가운데, 검색 키워드에 맞는 문서들을 찾아 낼 수 있을까요? 일반적인 선형검색을 떠올린다면 절대로 불가능한 속도라는 것을 알 수 있습니다.
엘라스틱 서치는 왜 빠를까?
엘라스틱 서치는 Apache Lucene기반의 오픈소스 '검색엔진'입니다. 그럼 엘라스틱 서치와 같은 검색엔진들은 왜 그렇게 빠른 걸까요?
MySQL과 같은 관계형 데이터베이스에 익숙하다면, 테이블이 인덱싱(색인작업) 되면 복잡한 쿼리에서 훨씬 더 나은 성능을 보여준다는 것을 잘 알고 계실겁니다. (인덱싱은 빠른 검색을 위해 필드값을 열이나 Document에게 매핑 된다는 것을 의미합니다.) 주어진 검색어에 대해서 모든 열을 찾아보는 대신에, 인덱스(색인)를 이용해서 어떤 문서나 열에 해당되는지 찾을 수 있습니다. 이것이 인덱스가 쿼리 속도를 엄청나게 빠르게 만드는 이유입니다.
그리고 엘라스틱 서치는 (검색어가 될 수 있는) 문자들을 유연하게 토큰화하고 인덱싱하는데 특화되어 있습니다. 예를 들어, "Hello to the world"라는 하나의 문자열을 다양한 방법으로 인덱싱을 진행 할 수 있습니다.
1.
["Hello to the world"]를 통채로 할 수 도 있고,
2.
["hello", "to", "the", "world"] 각각의 단어들로 할 수 도있고,
3.
["hello", "world"] 전치사나 관사를 빼버리고 의미있는 단어로만 할 수 도 있습니다.
4.
그리고, 사용자가 원하는 규칙에 따라 다른 방식도 만들어 낼 수 있습니다. 예를들어 "to"라는 전치사를 중요하게 생각한다면 추가 시킬 수도 있습니다.
이렇게 토큰화된 단어들이 인덱스 키가 되어 훨씬 빠르고 효율적인 문서 검색을 진행합니다.
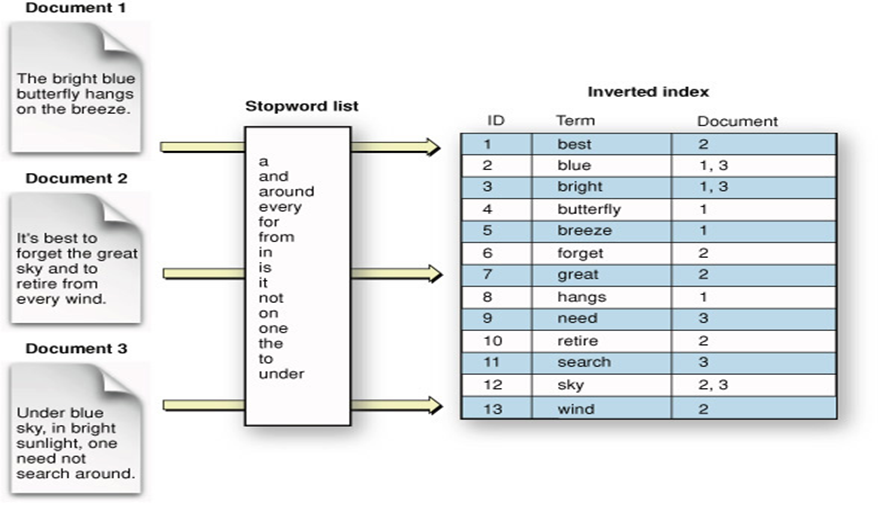
위에 사진을 보면 어떤 방식으로 문자열 (혹은 문서)가 단어별로 인덱싱되어 저장되는지 알 수 있습니다. 관사나 전치사등을 제외한 유의미한 키워드들을 추리고, 각 키워드가 어떤 Document에 저장되어 있는지 저장합니다. 이제 'best'라는 키워드로 검색을 진행하면 Document 2에서 best 라는 키워드가 사용되었음을 바로 알 수 있습니다. (만약 이를 선형 검색으로 진행한다면 Document 1, Document 2, Document 3에 모든 단어들을 하나씩 비교대조하여 찾아봐야 하겠죠?). 이런 구조라면 하나의 키워드를 찾을 때 마치 해쉬(hash) 테이블을 이용하는 것처럼 시간복잡도는 O(1)에 수렴하게 됩니다. 바로 실시간 검색이 가능한 이유입니다.
SQL데이터베이스들은 많은 인덱스를 다룰 때 성능이 저하되는 반면, 엘라스틱 서치는 복잡하고 상당한 양의 인덱스를 다루더라도 성능에 저하가 거의 없습니다. 그리고 찾은 데이터를 효과적으로 다루는 능력도 가지고 있습니다. (단순히 검색만 빠르다는게 아닙니다. 많은 개발자들이 빅데이터를 다루는데 엘라스틱 서치를 사용하는 이유가 또 있군요.)
엘라스틱 서치의 단점
1.
엘라스틱 서치는 SQL 데이터베이스보다 개별 레코드 검색을 수행하는 능력이 떨어지며, 특히 데이터를 업데이트 할 때는 성능이 크게 떨어집니다. 그러므로 만약 자주 정보를 업데이트 해야하는 애플리케이션이라면 엘라스틱 서치는 적절한 기술이 아닙니다.
2.
SQL 데이터베이스에서 테이블간의 조인을 수행하는 것처럼, Document간의 조인을 수행할 수 없습니다. 대신 조인을 수행하는 것처럼 2번의 별개로 수행해야 합니다. (2번의 쿼리를 수행하는 것이 SQL join 보다 빠를 순 있지만, 이런 행위를 누적해서 시행한다면 크게 느껴 질 수 있습니다.)